I reused my big file (USA.txt) and set up a benchmark run with a BufferedReader.
...
File f = new File("USA.txt");
FileInputStream fin = new FileInputStream(f);
BufferedReader in = new BufferedReader(new InputStreamReader(fin));
String s = "";
long start = System.currentTimeMillis();
while ( (s = in.readLine()) != null) {
int x = s.length();
}
long finish = System.currentTimeMillis();
System.out.println(finish - start);
...
The chart shows the performance of 100 runs of the code. It's pretty stable and hovers somewhere between 80 to 100 milliseconds.

Next step: get the InputStream up and running and compare. So, I went with a code block like so:
...
File f = new File("USA.txt");
InputStream in = new FileInputStream(f);
// buffSize configurable
byte[] buffer = new byte[buffSize];
int len = 0;
long start = System.currentTimeMillis();
while ( (len = in.read(buffer)) > 0 ) {
String s = new String(buffer, 0, len);
int x = s.length();
}
long finish = System.currentTimeMillis();
System.out.println(finish - start);
...
One of the drawbacks to the InputStream is that you can either read a byte at a time, or have to supply a byte read size. I started low, with a 16 byte sized array to read into. I could have been cute here, but I opted for simplicity. Here's how the 16 byte sized reads from the InputStream stacked up against the BufferedReader:
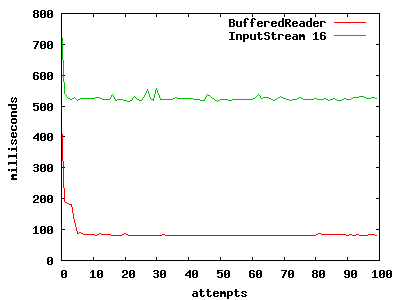
Not so hot, but not so surprising either. With such a small buffer size, I was surely choking the read speeds. So, I decided to try the runs with incrementing buffer sizes (32, 64, 265, 512, 1024, 2048 and 2086). And, here's what happened:

As we ratchet up the buffer size, we see performance gains. However, these gains steadily diminish. The most notable detail is that there's no point at which the InputStream read outperforms the BufferedReader. Behind the nice and friendly methods that the BufferedReader provides, there's clearly a huge amount of cool code that bridges the Reader to the InputStream. The cute parts that figure out the best way to read seem to be hidden, and working.
Spend some time reading through performance myths (from the pros), and there's one constant that shows up consistently. Keep it simple. The VMs do a lot of hard work for you, so you can write code that is clean. And, clearly this simplicity doesn't impose a performance burden here. Nifty.
Now, I wonder how much NIO helps...